
最近CELL杂志发表了一篇在植物中大规模检测蛋白互作的文章,介绍了检测的方法以及发布了数据库。文章的题目是“APan-plantProteinComplexMapRevealsDeepConservationandNovelAssemblies”。数据库的地址是:。
但对小麦来说,用起来不是特别友好。小麦基因的ID并不是我们常用的参考基因组ID,甚至需要通过水稻基因的ID对应过来。为了使用起来更方便,我们将该研究中使用的小麦基因id转换成了我们常用的中国春的基因id。具体是版本的注释ID,如。严格来说,是转录本ID,而去掉“.1”之后的ID才是基因ID,TraesCS6D02G084800。小麦多组学网站上线了很多在线的查询小工具,有的需要输入转录本ID,有的需要输入基因ID,有的是转录本ID;有的是1.0版本的ID,有的是2.0版本的ID。需要大家在使用过程中注意根据示例使用。
网址是,入口如下图所示。输入的格式是1.1版本的转录本ID,如。
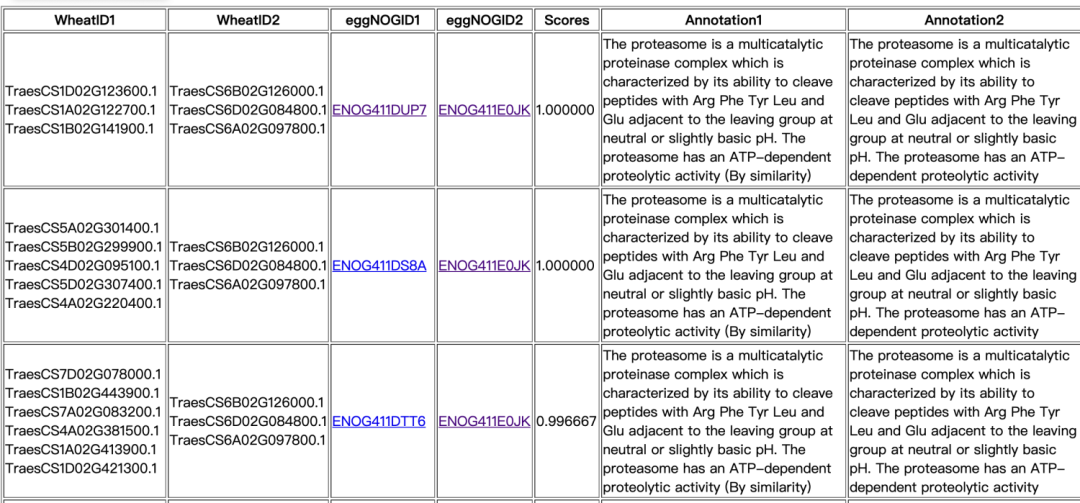
结果页面如下图所示,需要注意的是,结果中将小麦3个部分同源基因放在一组中。蛋白互作的可信度有Scores一栏的值(0~1)进行评价,越接近于1,结果越可信。
是不是很美好,蛋白互作动动手指,几秒就能获得。
然而,希望是美好的,现实是残酷的。很多文章中已发表的蛋白互作在这个数据里却查不到。
查的越多,心里越凉。是什么原因呢?
第二,从概率方面考虑。以小麦4万个基因(部分同源基因不算在内)为例,一共有多少种蛋白互作的可能呢,更何况一个蛋白可能有与其它N个蛋白形成复合体,不同阶段其互作的蛋白也可能不同。数据库仅仅包含了三百多万个互作,只占了很小很小一部分。在这种情况下,越是互作蛋白多的基因越容易检测到互作。
第三,系统有“缺陷”。这句话没有任何事实根据,是瞎说。这个检测系统有没有偏好性?
第四,考虑到准确性,数据库只收录了在多个物种中同时检测到的蛋白互作。那些在不同物种间功能不保守的蛋白也可能就漏掉了。
最后列出来,小麦的质谱数据,欢迎有能力的同志进行分析。








